

You can be searching for information on your car and get a similar experience.
Huh, thats weird. Your chatgpt output looks just like a google result page.
We need a human-curated Internet search. A wiki of good web content.
That is (was) DMOZ: the Mozilla Directory of websites, now curlie.org, after AOL shut it down in 2017.
They have a Patreon if you want to help them maintain it.
Oh cool, somebody signed up, they have more supporters today.
The return of web directories 🤩 https://en.m.wikipedia.org/wiki/Web_directory
Back to 90s internet you say?
Maybe web rings are due for a comeback.
Please.
I forgot how this worked until I discovered NeoCities. I suddenly remenbered when so many personal websites would have some page that’s like “links” or “sites I love” or “other cool people”, etc. And it was just a curated list of sites the author thought were neat.
And your bookmark function was actually really helpful, because “web surfing” was literally jumping from link to link to link, following rabbitholes and breadcrumb trails across the web.
Nowadays, I bookmark things but I never go back through them. I know Firefox sometimes automatically helps you remember stuff in your bookmarks though.
But there was a time when it felt like finding some niche site was a sort of secret club or cool treasure, and you had to make sure you could find your way back. :)
When you didn’t make the bookmark, you were basically trying to backtrack which links you followed and what sites you visited to get back to that one website.
Totally! And I loved those neat little animated web badges that became really popular, especially on forums.
I still have those on one of the forums I occasionally still visit, but it might disappear soon after nearly 2 and a half decades.
Kagi:

First result is the official documentation with the page that contains information about the in operator
This was the result: https://www.postgresql.org/docs/9.0/functions.html
BUT it is the documentation for 9.0
Though if I would use postgresql documentation very often I could just use the Kagi feature that rewrites URLs with a regex, so I can replace it always with the latest version.
Kagi Documentation for that feature:
https://help.kagi.com/kagi/features/redirects.html#redirects-url-rewrites
Some use cases of redirects include:
- Change domains to a preferred domain (reddit.com to old.reddit.com)
- Fixing links to outdated documentation with bad SEO
- Rewriting proxied pages (like Google AMP) to their source URL
- Changing any http link to https
Interesting, my Kagi results gave W3Schools, geeks for geeks, and postgresqltutorial.com before the official docs, but hey still way better than OP’s results!
Kagi has search personalization where you can lower/raise/pin specific domains (one of kagis main selling points) and I blocked geeks for geeks and w3schools, as these are irrelevant for me and I don’t want them in my results
can’t you do that on a self-hosted searxng? I know you can do that with YaCY, but YaCY search results kinda suck
I don’t think that’s possible with searxng (but I’m not 100% sure, but I can’t seem to find that feature)
I know there are browser extensions which can filter out domains in search results for different search engines like google and duckduckgo.
But the pinning/lowering/raising is a bit trickier to implement as an extension, because what kagi does is basically:
- Load 3 pages of search results in the backend
- Show a result as the first entry if it matches a rule for pinning
- Influence the search ranking algorithm with the lower/raise rules of the user
- Filter out blocked domains
It would be possible but not as “streamlined” as Kagi does.
Don’t get me wrong, Kagi definitely has its rough edges and the search ranking algorithm is sometimes very unpredictable, but it provides good enough results for me to be worth the 10$ per month for unlimited searches.
I searched for Magic The Gathering cards earlier on my phone (FireFox mobile), and got YouTube shorts in the results. This was in addition to a large amount of useless info panels and junk in the search results. I just wanted the official links or even an Amazon URL to the upcoming precons, not slowly regurgitated info!
I only use it for web stuff but W3Schools is usually pretty solid so I wouldn’t be mad having that as a first result.
Bing also grabs w3Schools as the top / AI result. However, the AI result also lets you swap to a Stack Overflow result.
And it has a bar across the top linking to different parts of the official website, including the landing page for the documentation.
Funny, we all used to avoid W3Schools because it was a heavily SEO’d ad farm, but nowadays it’s actually a Web 2.0 oasis in a hellscape of infinite scrolling AI bullshit. I’ve found myself using it over SO since their surrender to OpenAI.
Web 2.0 oasis
💀
It pisses me off that Java’s class library documentation is at a totally different URL for every version. You can’t just change 11 to 21 in the URL.
I definitely feel the pain when it comes to worthless results nowadays. Though in this case DDG comes through:
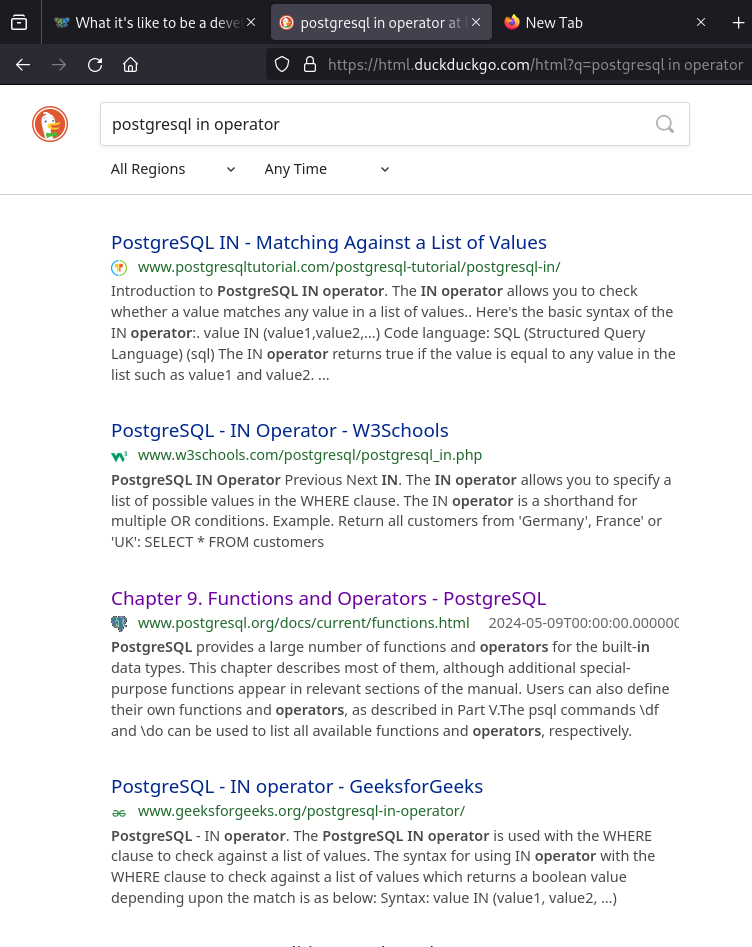
Adding documentation to the search makes the “correct” page soar to the top:

Haha, nope. The links points to a table of contents after which you are on your own. The right link should point to a specific page instead, but the problem here is that postres docs are poorly optimized for search engines. If you click on the top link from google, you would see there’s a notice that the page is outdated, with a link to a current version, but said link is dead. It’s not an issue I’ve ever experienced with mysql docs for example.
And yes, w3schools, despite how terrible it is, is still above the official docs because it is more popular with newbies. I remember a time when I just started, I preferred sites like it, because they were simple and on point, rather than technically correct and comprehensive like the official docs are. If you forgot the feeling, try learning math on wikipedia (assuming you don’t have a math degree).
For the rest I cannot argue. Generated/AI shit is indeed ruining the internet and search engines giving up and joining them isn’t helpful either.
Trying to learn math on Wikipedia is an endless Sisyphean nightmare just trying to understand the first word in an unfamiliar vocabulary.
After which ctrl+f " in" takes you to the correct chapters. I do agree that a direct link would be more helpful.
And for learning postgresql I agree it isn’t very helpful - using their tutorial links, w3schools or something like udemy if you prefer video format is the way to go in that use case.I remember back when you were told to learn to work with the documentation, not memorize it, because you will always have access to it as a reference. Maybe bookmarking reference books/documentation will make a come back as the search engines degrade.
Surely the word ‘in’ would appear countless times out of context on the table of contents.
" in" appears 25 times on the page to be exact, with 16 of those being in the table of contents and 9 being in the text afterwards.
“in” appears 54 times, as you know end up hitting “string” and so on.Had I known that the functions table of contents was as short as it is I would probably have just scrolled.
This is partly why I prefer Firefox’s implementation of the find feature - it allows case-sensitive search while Chrome does not support it.
You can press alt-w though to only show full word matches
Google is better as a verb than a search engine.
I use “search” as a verb

Kagi only lists postgresql.org for the first 10 entries, but outdated ones in first place. With the programming scope it collapses all official do s entries to one, with GH and SO filling the rest.
For the quick answer, it also uses the ‘outdated’ docs as source, but as it only gives a very shallow overview there shouldn’t be any difference in version (i.e. it checks for a value in a list in all versions the same, and quick answer leaves out details specific to different versions)
So many SEO trick to put yourselves into top google search for traffic.
I have google for bug and stuff, and most common bug can be found on shitty content Java tip page with broken format, lot of ads, and sometime untrue/outdate information.
This is why I jumped ship to DuckDuckGo like 4-5 years ago already, never looked back
Coincidentally, yesterday I was quickly setting up a new computer for some testing whilst talking to somebody about another so I was half distracted. I did a search for some package to install and got absolute unusable crap. I didn’t understand, tried again, tried different search parameters and it just got worse, and then I noticed that, since this was a new computer, the browser was using google.
I switched to DDG, and first page first hit was what I needed.
DDG also has been in a steady decline and apparently has been using Bing as it’s back-end now. I’d love to use a self hosted open source browser, or of not that, an open source federated search engine, akin to Lemmy, but I don’t see either coming into existence anytime soon.
apparently has been using Bing as it’s back-end now.
A lot of stuff uses Bing to search, as it’s the largest search engine with an official public API that any developer can just sign up and use. Voice assistants like Alexa use Bing too.
Is… Is Microsoft the good guy here? Tell me it ain’t so!
DDG always used bing backend tho, what’s happening is bing backend worsening
bing itself is unusable tho. I get a full page of “sponsored links” before any tentatively relevant search result pop up. DDG at least removes the sponsored bullshit.
Someyhing like searxng? Or what do you imagine?
it already exists and it’s called Yacy, an open source decentralized search engine
For what it’s worth, DDG isn’t perfect either. There are plenty of times I have to use Google instead. I don’t keep track of how often it anything but it’s definitely not perfect.
Well, that is what I said. Dog isn’t as great as it used to be
as its* back end now
Yeah, auto correct isn’t my friend
searx is around for a couple of years now.
Some of this is just because some of these frameworks and technologies have been around for a while and they iterate frequently. I see a ton of Azure content that is obsolete after only a few years.
Third result in DDG.
deleted by creator
Because Google decided years ago that relevancy is less important than profitability.
Who are they profiting off of? I have never clicked an ad in my entire life.
Doesn’t matter, billions of other people do, and they prioritize ads, and results with AdSense on the pages above relevancy. They’ll even show you shit results to keep you searching longer, which allows them to show you more ads.
Do they though? I don’t know a single person that has ever clicked on an ad. I know, sample size of one, but it just seems so basic to know not to click on them. Maybe those people really do exist. Sigh
Do you think Google has become one of the most powerful & profitable companies on the planet through a revenue model that doesn’t work? Of course people click them. If people didn’t click them then Google would have gone bankrupt decades ago. One thing I learned years ago is that I use the Internet very differently than an average person, and I constantly overestimate the intelligence and knowledge of the average person. Corporations bank on stupidity, because it’s abundant.
I have no idea how they make money, it never made sense to me. It still blows my mind to think there are that many people that click on ads, I just have a really hard time believing it still.
Some of the ads are charged by CPM (cost per 1000 impressions), meaning Google get paid just because people see the ads. That’s similar to how ads in traditional media are billed - TV, billboards, newspapers, etc.
Not all ads use CPM though. Some use CPC (cost per click) and some use CPA (cost per action).
I get quite a bit of flak from my colleagues for paying for search, but I kid you not, I don’t regret splurging on a Kagi subscription at all. It’s personally less stressful for me, having to wade through less cruft, and I think I even work significantly faster because of how I use it.
It’s sad when you think about it. Search was such a good experience in the past.
deleted by creator
I also pay for Kagi and I’m super happy with that decision. I do wish they’d stop putting so much AI cruft into their search engine, but at least I can disable it.
With most topics, I find fastgpt to be the most up to date, accurate and best sourced. And with just a normal search there’s basically just one expandable strip with AI, no real annoyance for me.
I was against the ai integrations until I started actually trying them… quick answers are awesome.

Stop using google.
DuckDuckGo is also being poisoned by SEO unfortunately. Some group of people managed to crack its algorithm, and as Google is slowly but fading relevancy, DuckDuckGo is now also has the same issues.
I’ve been using Kagi for a year and am happy with it
Thank you, I’ll be checking it out
For me even kagi didn’t provide a recent doc, but at least there is no garbage-sites (which I have blocked)
Yeah it’s getting worse too. It’s still far better than google, for now anyway.






{kind=link}