OpenAI now tries to hide that ChatGPT was trained on copyrighted books, including J.K. Rowling’s Harry Potter series::A new research paper laid out ways in which AI developers should try and avoid showing LLMs have been trained on copyrighted material.
OpenAI has stated that its models were trained on publicly available and licensed data. There is no confirmed evidence that ChatGPT was specifically trained on copyrighted books like J.K. Rowling’s Harry Potter series. The company has not disclosed the full details of its training data.
This is just OpenAI covering their ass by attempting to block the most egregious and obvious outputs in legal gray areas, something they’ve been doing for a while, hence why their AI models are known to be massively censored. I wouldn’t call that ‘hiding’. It’s kind of hard to hide it was trained on copyrighted material, since that’s common knowledge, really.
I don’t get why this is an issue. Assuming they purchased a legal copy that it was trained on then what’s the problem? Like really. What does it matter that it knows a certain book from cover to cover or is able to imitate art styles etc. That’s exactly what people do too. We’re just not quite as good at it.
ssuming they purchased a legal copy that it was trained on then what’s the problem?
i never purchased a copy of harry potter i got a loaner. now what?
A copyright holder has the right to control who has the right to create derivative works based on their copyright. If you want to take someone’s copyright and use it to create something else, you need permission from the copyright holder.
The one major exception is Fair Use. It is unlikely that AI training is a fair use. However this point has not been adjudicated in a court as far as I am aware.
this is so fucking stupid though. almost everyone reads books and/or watches movies, and their speech is developed from that. the way we speak is modeled after characters and dialogue in books. the way we think is often from books. do we track down what percentage of each sentence comes from what book every time we think or talk?
Aye, but I’m thinking the whole notion of copyright is banking on the fact that human beings are inherently lazy and not everyone will start churning out books in the same universe or style. And if they do, it takes quite some time to get the finished product and they just get sued for it. It’s easy, because there’s a single target.
So there’s an extra deterrent to people writing and publishing a new harry potter novel, unaffiliated with the current owner of the copyright. Invest all that time and resources just to be sued? Nah…
Issue with generating stuff with 'puters is that you invest way less time, so the same issue pops up for the copyright owner, they’re just DDoS-ed on their possible attack routes. Will they really sue thousands or hundreds of thoudands of internet randos generating harry potter erotica using a LLM? Would you even know who they are? People can hide money away in Switzerland from entite governments, I’m sure there are ways to hide your identity from a book publisher.
It was never about the content, it’s about the opportunities the technology provides to halt the gears of the system that works to enforce questionable laws. So they’re nipping it in the bud.
this brings up the question: what is a book? what is art? if an “AI” can now churn out the next harry potter sequel and people literally can’t tell that it’s not written by JK Rowling, then what does that mean for what people value in stories? what is a story? is this a sign that we humans should figure something new out, instead of reacting according to an outdated protocol?
yes, authors made money in the past before AI. now that we have AI and most people can get satisfied by a book written by AI, what will differentiate human authors from AI? will it become a niche thing, where some people can tell the difference and they prefer human authors? or will there be some small number of exceptional authors who can produce something that is obviously different from AI?
i see this as an opportunity for artists to compete with AI, rather than say “hey! no fair! he can think and write faster than me!”
Well, poor literature has always existed, which some might not even dignify to call literature. Are writers of such things threatened by LLMs? Of course they are. Every new technology has beought with it the fear of upending somebody’s world. And to some extent, every new technology has indeed done just that.
Personally, and… this will probably be highly unpopular, I honestly don’t care who or what created a piece of art. Is it pretty? Does it satisfy my need for just the right amount of weird, funny and disturbing to stir emotions or make me go ‘heh, interesting!’? Then it really doesn’t matter where it comes from. We put way too much emphasis on the pedigree of art and not on the content. Hell, one very nice short story I read was the greentext one about humans being AI and escaping from the simulation. Wonder how many would scoff at calling art something that came out of 4chan?
Maybe this is the issue? Art is thought of as a purely human endeavour (also birds do it, and that one pufferfish that draws on the seabed, but they’re “dumb” animals so they don’t count, right? hell, there’s even a jumping spider that does some pretty rad dances). And if code in a machine can do it just as well (can it? let it - we’ll be all the better for it. can’t it? let it be then - no issue) then what would be the significance of being human?
It is not a derivative it is transformative work. Just like human artists “synthesise” art they see around them and make new art, so do LLMs.
LLMs don’t create anything new. They have limited access to what they can be based on, and all assumptions made by it are based on that data. They do not learn new things or present new ideas. Only ideas that have been already done and are present in their training.
Transformative works are not a thing.
If you copy the copyrightable elements of another work, you have created a derivative work. That work needs to be transformative in order to be eligible for its own copyright, but being transformative alone is not enough to make it non-infringing.
There are four fair use factors. Transformativeness is only considered by one of them. That is not enough to make a fair use.
Transformativeness is only considered by one of them. That is not enough to make a fair use.
Somebody better let YouTube content creators know that. /s
The powers that be have done a great job convincing the layperson that copyright is about protecting artists and not publishers. It’s historically inaccurate and you can discover that copyright law was pushed by publishers who did not want authors keeping second hand manuscripts of works they sold to publishing companies.
Additional reading: https://en.m.wikipedia.org/wiki/Statute_of_Anne
Lol, oh my gosh guys, it’s true. This is a (error ridden) line from dobby.
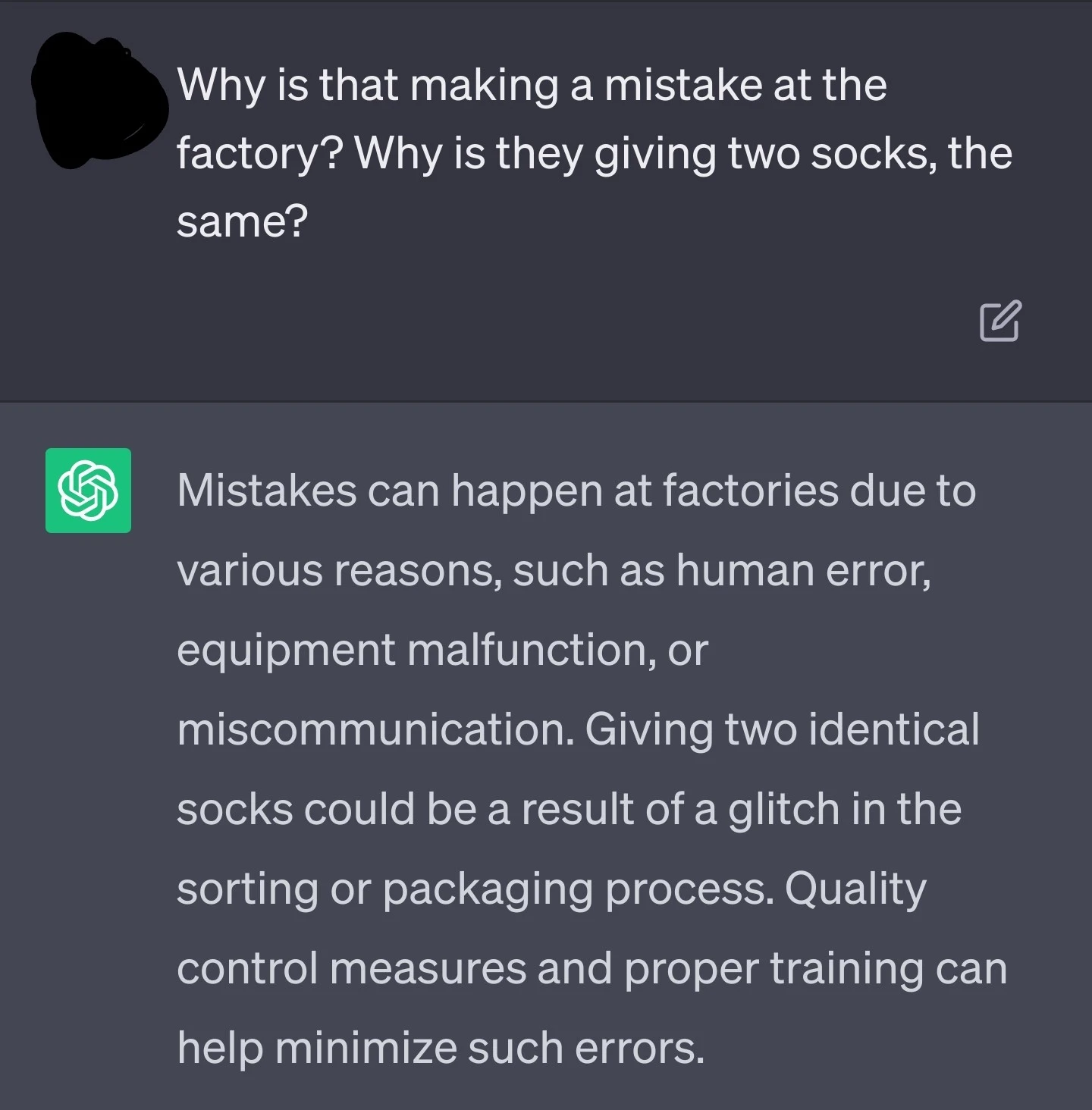
Edit: I’m sorry, but I can’t stop laughing. This is amazing. I can’t stop… I won’t stop.
Why are people defending a massive corporation that admits it is attempting to create something that will give them unparalleled power if they are successful?
Because everyone learns from books, it’s stupid.
An LLM is not a person, it is a product. It doesn’t matter that it “learns” like a human - at the end of the day, it is a product created by a corporation that used other people’s work, with the capacity to disrupt the market that those folks’ work competes in.
And it should be able to freely use anything that’s available to it. These massive corporations and entities have exploited all the free spaces to advertise and sell us their own products and are now sour.
If they had their way they are going to lock up much more of the net behind paywalls. Everybody should be with the LLMs on this.
If they had their way they are going to lock up much more of the net behind paywalls.
This!
When the Internet was first a thing corpos tried to put everything behind paywalls, and we pushed back and won.
Now, the next generation is advocating to put everything behind a paywall again?
Except the massive corporations and entities are the ones getting rich on this. They’re seeking to exploit the work of authors and musicians and artists.
Respecting the intellectual property of creative workers is the anti corporate position here.
Except corporations have infinitely more resources(money, lawyers) compared to people who create. Take Jarek Duda(mathematician from Poland) and Microsoft as an example. He created new compression algorythm, and Microsoft came few years later and patented it in Britain AFAIK. To file patent contest and prior art he needs 100k£.
I think there’s an important distinction to make here between patents and copyright. Patents are the issue with corporations, and I couldn’t care less if AI consumed all that.
And for copyright there is no possible way to contest it. Also when copyright expires there is no guarantee it will be accessable by humanity. Patents are bad, copyright even worse.
Large number of these Artist, musicians and authors is corporate America today. And those authors artists and musicians have exploited all our spaces for far too long. Most of the internet had been turned toxic due to their greed. I wish they take their content and go find their own spaces instead of mooching off everybody else’s. These LLMs are only doing what they’ve done
I’m sorry, what?
There is nothing anti corporate if result can be alienated.
You are somehow conflating “massive corporation” with “independent creator,” while also not recognizing that successful LLM implementations are and will be run by massive corporations, and eventually plagued with ads and paywalls.
People that make things should be allowed payment for their time and the value they provide their customer.
People are paid. But they’re greedy and expect far more compensation then they deserve. In this case they should not be compensated for having an LLM ingest their work work if that work was legally owned or obtained
How are we going to make ai, if it can’t learn?
First, we don’t have to make AI.
Second, it’s not about it being unable to learn, it’s about the fact that they aren’t paying the people who are teaching it.
Then give the AI a library card, feel better?
Humans can judge information make decisions on it and adapt it. AI mostly just looks at what is statistically what is most likely based on training data. If 1 piece of data exists, it will copy, not paraphrase. Example was from I think copilot where it just printed out the code and comments from an old game verbatim. I think Quake2. It isn’t intelligence, it is statistical copying.
Well, mathematics cannot be copyrighted. In most countries at least.
The reasoning that claims training a generative model is infringing IP would still mean a robot going into a library with a card it has to optically read all the books there to create the same generative model would still be infringing IP.
Same way that counting cards is illegal
yeah lets not explore this technology because it might hurt some copyrights holders
LOOOOL fuck em
because it might hurt authors and musicians and artists and other creative workers
FTFY. Corporations shouldn’t be making a fucking dime from any of these works without fairly paying the creators.
Leftists hating on AI while dreaming of post-scarcity will never not be funny
Mostly because fuck corporations trying to milk their copyright. I have no particular love for OpenAI (though I do like their product), but I do have great distain for already-successful corporations that would hold back the progress of humanity because they didn’t get paid (again).
There’s a massive difference though between corporations milking copyright and authors/musicians/artists wanting their copyright respected. All I see here is a corporation milking copyrighted works by creative individuals.
deleted by creator
But OpenAI will do the same?
In the United States there was a judgement made the other day saying that works created soley by AI are not copyright-able. So that that would put a speed bumb there.
I may have misunderstood what you though.Yeah, they might not copyright it, but after it becomes the ‘one true AI’, it will be at the hands of Microsoft, so please do not act friendly towards them.
It will turn on you just like every private company has.
(don’t mean specifically you, but everyone generally)
Huh. Doesn’t this means technically AI cannot do copyright infringement.
Nah, it would mean that you cannot copyright a work created by an AI, such as a piece of art.
E.g. if you tell it to draw you a donkey carting avocados, the picture can be used by anyone from what I understand.
you cannot copyright a work created by an AI, such as a piece of art.
That’s what I said. Copyright infringement is when there is another copyrightable object that is copy of first object. AI is not witin copyright area. You can’t copyright it, but also you can’t be sued for copyright infringement too.
if you tell it to draw you a donkey carting avocados, the picture can be used by anyone from what I understand.
Yes. Same for Public Domain, but PD is another status. PD applies only to copyrightable work.
It’s like argument “but new politicians will steal more” that I hear in Russia from people who protect Putin
It’s literally not, wtf.
Do not let any private entity to get overwhelming majority on anything period.
But do not kid yourself that Microsoft will let OpenAI do anything for public once it gets big enough.
OpenAI is open only in name after they rolled back all the promises of being for everyone.
That’s my entire point. It’s not who, but how long.
Also Microsoft plays both sides here. OpenAI vs copyright is wrong question. There’s more: both are status-quo. Both are for keeping corporate ownership of ideas.
Perhaps, and when that happens I would be equally disdainful towards them.
The dream would be that they manage to make their own glorious free & open source version, so that after a brief spike in corporate profit as they fire all their writers and artists, suddenly nobody needs those corps anymore because EVERYONE gets access to the same tools - if everyone has the ability to churn out massive content without hiring anyone, that theoretically favors those who never had the capital to hire people to begin with, far more than those who did the hiring.
Of course, this stance doesn’t really have an answer for any of the other problems involved in the tech, not the least of which is that there’s bigger issues at play than just “content”.
i think trying to keep this cat in the bag is jsut a waste of time. plus i dont respect copyright sooo…
AI is the new fan boy following since it became official that nfts are all fucking scams. They need a new technological God to push to feel superior to everyone else…
Are you ok? You seem upset
Because ultimately, it’s about the truth of things, and not what team is winning or losing.
Google AI search preview seems to brazenly steal text from search results. Frequently its answers are the same word for word as a one of the snippets lower on the page
So that explains the “problematic” responses.
They made it read Harry Potter? No wonder its gonna kill us all one day.
Vanilla Ice had it right all along. Nobody gives a shit about copyright until big money is involved.
If it’s infringing on JK Rowling’s work, then it’s fine
If I memorize the text of Harry Potter, my brain does not thereby become a copyright infringement.
A copyright infringement only occurs if I then reproduce that text, e.g. by writing it down or reciting it in a public performance.
Training an LLM from a corpus that includes a piece of copyrighted material does not necessarily produce a work that is legally a derivative work of that copyrighted material. The copyright status of that LLM’s “brain” has not yet been adjudicated by any court anywhere.
If the developers have taken steps to ensure that the LLM cannot recite copyrighted material, that should count in their favor, not against them. Calling it “hiding” is backwards.
you bought the book to memorize from, anyway.
No, I shoplifted it from an Aldi
Another sensationalist title. The article makes it clear that the problem is users reconstructing large portions of a copyrighted work word for word. OpenAI is trying to implement a solution that prevents ChatGPT from regurgitating entire copyrighted works using “maliciously designed” prompts. OpenAI doesn’t hide the fact that these tools were trained using copyrighted works and legally it probably isn’t an issue.
Let’s not pretend that LLMs are like people where you’d read a bunch of books and draw inspiration from them. An LLM does not think nor does it have an actual creative process like we do. It should still be a breach of copyright.
*could
… you’re getting into philosophical territory here. The plain fact is that LLMs generate cohesive text that is original and doesn’t occur in their training sets, and it’s very hard if not impossible to get them to quote back copyrighted source material to you verbatim. Whether you want to call that “creativity” or not is up to you, but it certainly seems to disqualify the notion that LLMs commit copyright infringement.
This topic is fascinating.
I really do think i understand both sides here and want to find the hard line that seperates man from machine.
But it feels, to me, that some philosophical discussion may be required. Art is not something that is just manufactured. “Created” is the word to use without quotation marks. Or maybe not, i don’t know…
I wasn’t referring to whether the LLM commits copyright infringement when creating a text (though that’s an interesting topic as well), but rather the act of feeding it the texts. My point was that it is not like us in a sense that we read and draw inspiration from it. It’s just taking texts and digesting them. And also, from a privacy standpoint, I feel kind of disgusted at the thought of LLMs having used comments such as these ones (not exactly these, but you get it), for this purpose as well, without any sort of permission on our part.
That’s mainly my issue, the fact that they have done so the usual capitalistic way: it’s easier to ask for forgiveness than to ask for permission.
I think you’re putting too much faith in humans here. As best we can tell the only difference between how we compute and what these models do is scale and complexity. Your brain often lies to you and makes up reasoning behind your actions after the fact. We’re just complex networks doing math.
but rather the act of feeding it the texts.
Unless you are going to argue the act of feeding it the texts is distributing the original text or doing some kind of public performance of the text, I don’t see how.
If Google took samples from millions of different songs that were under copyright and created a website that allowed users to mix them together into new songs, they would be sued into oblivion before you could say “unauthorized reproduction.”
You simply cannot compare one single person memorizing a book to corporations feeding literally millions of pieces of copyrighted material into a blender and acting like the resulting sausage is fine because “only a few rats fell into the vat, what’s the big deal”
Terrible analogy.
Which one? And why exactly?
The analogy talks about mixing samples of music together to make new music, but that’s not what is happening in real life.
The computers learn human language from the source material, but they are not referencing the source material when creating responses. They create new, original responses which do not appear in any of the source material.
“Learn” is debatable in this usage. It is trained on data and the model creates a set of values that you can apply that produce an output similar to human speach. It’s just doing math though. It’s not like a human learns. It doesn’t care about context or meaning or anything else.
Okay, but in the context of this conversation about copyright I don’t think the learning part is as important as the reproduction part.
Google crawls every link available on all websites to index and give to people. That’s a better example. Which is legal and up to the websites to protect their stuff
It’s not a problem that it reads something. The problem is the thing that it produces should break copyright. Google search is not producing something, it reads everything to link you to that original copyrighted work. If it read it and then just spit out what’s read on its own, instead of sending you to the original creators, that wouldn’t be OK.
How is it reproducing the works
The blurb it puts out in the search results is much more directly “spitting out what’s read” than anything an LLM does. As are most other srts of results that appear on the front page of a google search.
You are a human, you are allowed to create derivative works under the law. Copyright law as it relates to machines regurgitating what humans have created is fundamentally different. Future legislation will have to address a lot of the nuance of this issue.
And allowed get sued anyway
I am sure they have patched it by now but at one point I was able to get chatgpt to give me copyright text from books by asking for ever large quotations. It seemed more willing to do this with books out of print.
Yeah, it refuses to give you the first sentence from Harry Potter now.
Which is kinda lame, you can find that on thousands of webpages. Many of which the system indexed.
If someone was looking to pirate the book there are way easier ways than issuing thousands of queries to ChatGPT. Type “Harry Potter torrent” into Google and you will have them all in 30 seconds.
ChatGPT has a ton of extra query qualifiers added behind the scenes to ensure that specific outputs can’t happen
Training AI on copyrighted material is no more illegal or unethical than training human beings on copyrighted material (from library books or borrowed books, nonetheless!). And trying to challenge the veracity of generative AI systems on the notion that it was trained on copyrighted material only raises the specter that IP law has lost its validity as a public good.
The only valid concern about generative AI is that it could displace human workers (or swap out skilled jobs for menial ones) which is a problem because our society recognizes the value of human beings only in their capacity to provide a compensation-worthy service to people with money.
The problem is this is a shitty, unethical way to determine who gets to survive and who doesn’t. All the current controversy about generative AI does is kick this can down the road a bit. But we’re going to have to address soon that our monied elites will be glad to dispose of the rest of us as soon as they can.
Also, amateur creators are as good as professionals, given the same resources. Maybe we should look at creating content by other means than for-profit companies.
Also this argument if replacing human workers has been made with every single industrial revolution.
and it has happened every single time? what do you mean?
The point is fighting back against it is stupid. The point is people still have work. New technology opens up new was to work with new jobs.
I hope OpenAI and JK Rowling take each other down
Sticky this comment
What’s the issue against openAI?
They used to be a non profit, that immediately turned it into a for profit when their product was refined. They took a bunch of people’s effort whether it be training materials or training Monkeys using the product and then slapped a huge price tag on it.
I didn’t know they were a non profit. I’m good as long as they keep the current model. Release older models free to use while charging for extra or latest features
They’re stealing a ridiculous amount of copyrighted works to use to train their model without the consent of the copyright holders.
This includes the single person operations creating art that’s being used to feed the models that will take their jobs.
OpenAI should not be allowed to train on copyrighted material without paying a licensing fee at minimum.
Also Sam Altman is a grifter who gives people in need small amounts of monopoly money to get their biometric data
deleted by creator
He’s not helping them. That’s my point. He’s taking advantage of them for his grift, so fuck him.
deleted by creator
So hypothetical here. If Dreddit did launch a system that made it so users could trade Karma in for real currency or some alternative, does that mean that all fan fictions and all other fan boy account created material would become copyright infringement as they are now making money off the original works?
If they purchased the data or the data is free its theirs to do what they want without violating the copyright like reselling the original work as their own. Training off it should not violate any copyright if the work was available for free or purchased by at least one person involved. Capitalism should work both ways
But they don’t purchase the data. That’s the whole problem.
And copyright is absolutely violated by training off it. It’s being used to make money and no longer falls under even the widest interpretation of free use.
You need to expand on how learning from something to make money is somehow using the original material to make money. Considering that’s how art works in general, I’m having a hard time taking the side of “learning from media to make your own is against copyright”. As long as they don’t reproduce the same thing as the original, I don’t see any issues with it. If they learned from Lord of the rings to then make “the Lord of the rings” then yes, that’d be infringement. But if they use that data to make a new IP with original ideas, then how is that bad for the world/ artists.
Creating an AI model is a commercial work. They’re made to make money. Now these models are dependent on other artists data to train on. The models would be useless if they weren’t able to train on anything.
I hold the stance that using copyrighted data as part of a training set is a violation of copyright. That still hasn’t been fully challenged in court, so there’s no specific legal definition yet.
Due to the requirement of copywritten materials to make the model function I feel that they are using copyrighted works in order to build a commercial product.
Also AI doesn’t learn. LLMs build statistical models based on sentence structure of what they’ve seen before. There’s no level of understanding or inherent knowledge, and there’s nothing new being added.
deleted by creator