

Another day, another update.
More troubleshooting was done today. What did we do:
- Yesterday evening @phiresky@[email protected] did some SQL troubleshooting with some of the lemmy.world admins. After that, phiresky submitted some PRs to github.
- @[email protected] created a docker image containing 3PR’s: Disable retry queue, Get follower Inbox Fix, Admin Index Fix
- We started using this image, and saw a big drop in CPU usage and disk load.
- We saw thousands of errors per minute in the nginx log for old clients trying to access the websockets (which were removed in 0.18), so we added a
return 404in nginx conf for/api/v3/ws. - We updated lemmy-ui from RC7 to RC10 which fixed a lot, among which the issue with replying to DMs
- We found that the many 502-errors were caused by an issue in Lemmy/markdown-it.actix or whatever, causing nginx to temporarily mark an upstream to be dead. As a workaround we can either 1.) Only use 1 container or 2.) set
proxy_next_upstream timeout;max_fails=5in nginx.
Currently we’re running with 1 lemmy container, so the 502-errors are completely gone so far, and because of the fixes in the Lemmy code everything seems to be running smooth. If needed we could spin up a second lemmy container using the proxy_next_upstream timeout;max_fails=5 workaround but for now it seems to hold with 1.
Thanks to @[email protected] , @[email protected] , @[email protected], @[email protected] , @[email protected] , @[email protected] for their help!
And not to forget, thanks to @[email protected] and @[email protected] for their continuing hard work on Lemmy!
And thank you all for your patience, we’ll keep working on it!
Oh, and as bonus, an image (thanks Phiresky!) of the change in bandwidth after implementing the new Lemmy docker image with the PRs.
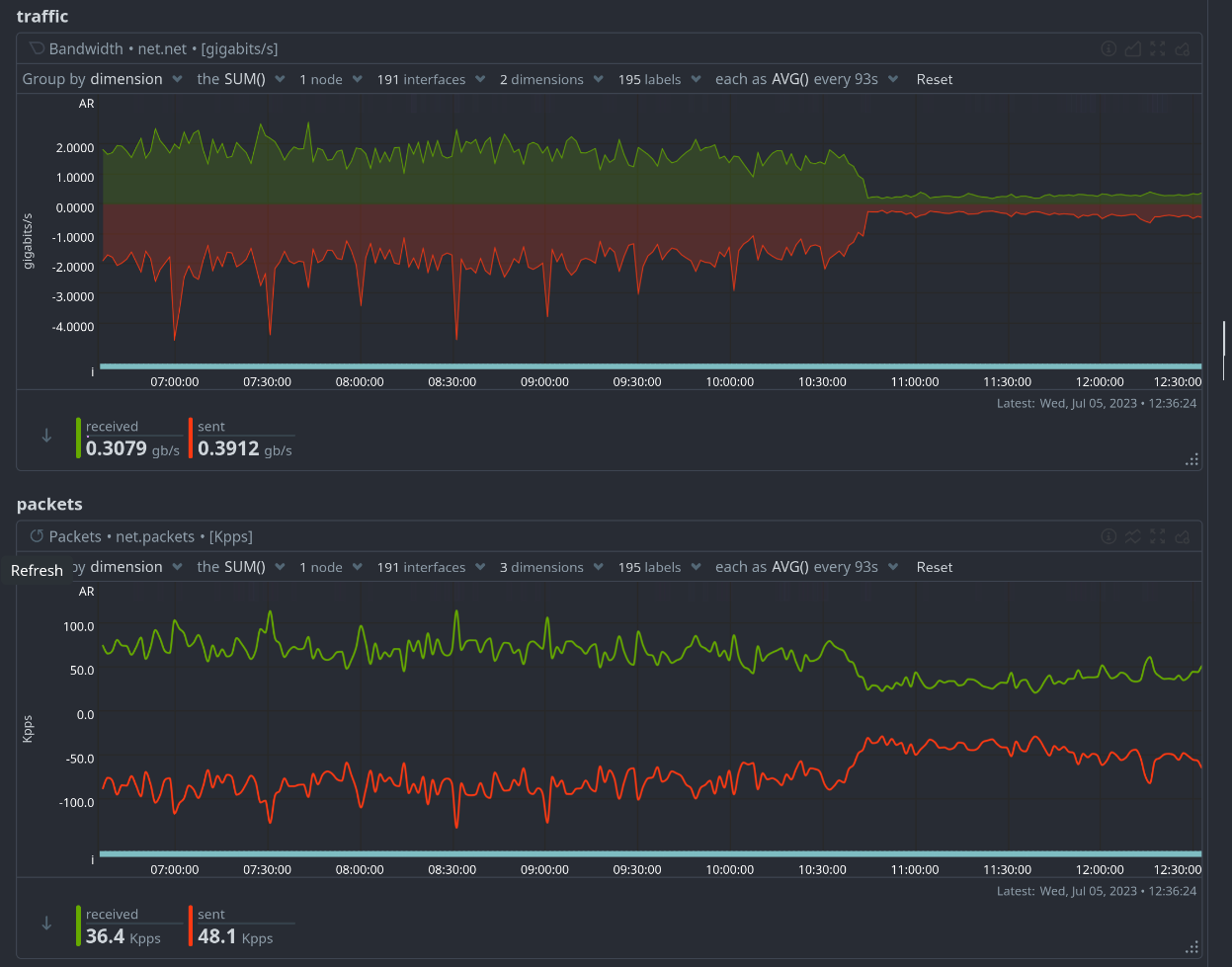
Edit So as soon as the US folks wake up (hi!) we seem to need the second Lemmy container for performance. So that’s now started, and I noticed the proxy_next_upstream timeout setting didn’t work (or I didn’t set it properly) so I used max_fails=5 for each upstream, that does actually work.
Great work!
Great job guys! It really feels more responsive today
I can’t imagine the amount of work Lemmy’s devs and ITs are under since few days, but those are important for the future of Lemmy. Keep the good work! You’re awesome!
It’s definitely snappier than before. Constantly having to refresh got old quick.
Are you guys able to create reports? I am not… It keeps spinning.
Can confirm, having way less problem browsing lemmy right now. Thank you admins!
It now feels pretty good to browse and it now makes the experience of using Lemmy much more enjoyable. Having to spam the vote buttons was really annoying.
The vote button change was also the one I immediately noticed!
I like that the post goes in detail and allows us tech nerds to get hard watching this stuff instead of the regular corpo jumbo change log that consists of:
- we uhh fixed some stuff so yeah good?
Test:
Upvote if you can see this comment. 👍
Shame you’re getting no karma. Take my upvote.
Oh, I thought that was the joke 😅
Like a tongue-in-cheek, remember our silly old Reddit ways kinda thing.
Ha. I don’t miss it. I upvote for good content.
I think i was on r for a year or two before I learned what karma was. I still don’t understand it’s value.
Can’t see anything…
502, sorry mate.
Damn, better luck next time.
Looking good from here.
Edit: And comment rapidly going through. :)
I can see and upvote this comment. 👍
I can also see and updoot yours. 👍
Using [email protected]
Commenting took about 3 seconds
Editing took about 0.8-2 seconds
(up/down)voting took about 1 second
Seemed to be running a lot smoother, thank you Ruud!
It’s very much helping the third party apps as well. Memmy is running way smoother now
Things feel a ton better today. Thank you for all the hard work!
Not that it really matters, but did anyone else notice their comment/post points get deleted after this update? Seems odd.
What points?
Its not on the default lemmy-ui on the web, but many third party apps for lemmy are showing total comment and post “scores” on user’s profile pages. Not exactly sure how they are calculating that, but ive noticed that those scores were wiped for at least my account today. Again, not a big deal, just thought it was strange how that would happen. It is showing like this in memmy as well as wefwef so it’s definitely some data out in the lemmy verse that went bad. it is starting to “count” stuff from comments ive made today though so, who knows.
Hmm that’s odd. @[email protected] do you know why score counts are wiped? I have no clue how they are calculated.
It looks like on the person_view counts object API response coming back from Lemmy.world, the amounts for scores are not right. Hmmm
Ever since I joined Lemmy I had problems posting replies but that kink seems to have been ironed out. Thanks!










