
US corporate sector throwing a tantrum when it gets beat at it’s own game.
“The free market auto-regulates itself” motherfuckers when the free market auto-regulates itself
Also, don’t forget that all the other AI services are also setting artificially low prices to bait customers and enshittify later.
I wasn’t under the impression American AI was profitable either. I thought it was held up by VC funding and over valued stock. I may be wrong though. Haven’t done a deep dive on it.
Okay, I literally didn’t even post the comment yet and did the most shallow of dives. Open AI is not profitable. https://www.cnbc.com/2024/09/27/openai-sees-5-billion-loss-this-year-on-3point7-billion-in-revenue.html
To the rich being overvalued and being profitable are indistinguishable.
I get your point, but I mean the business being profitable from an accounting perspective, not the stock being profitable from an investing perspective.
The CEO said on twitter that even their $200/month pro plan was losing money on every customer: https://techcrunch.com/2025/01/05/openai-is-losing-money-on-its-pricey-chatgpt-pro-plan-ceo-sam-altman-says/
I don’t see how they would become profitable any time soon if their costs are that high. Maybe if they adapt the innovations of deepseek to their own model.
Haven’t done a deep dive on it.
deep seek you mean?
👉😎👉
I mean it seems to do a lot of Chine-related censoring but it seems to otherwise be pretty good
If they are admittedly censoring, how can you tell what is censored and what’s not?
I guess you can test it with stuff you know the answer to.
If you use the model it literally tells where it will not tell something to the user. Same as guardrails on any other LLM model on the market. Just different topics are censored.
So we are relying on the censor to tells us what they don’t censor?
AFAIK, and I am open to being corrected, the American models seem to mostly negate requests regarding current political discussions (I am not sure if this is still true even), but I don’t think they taboo other topics (besides violence, drug/explosives manufacturing, and harmful sexual conducts).
I don’t think they taboo some topics but I’m sure the model has a bias specific to what people say in the internet. Which might not be correct according to people who challenge some views on historical facts.
Of course Chinese censorship is super obvious and made by design. American is rather a side effect of some cultural facts or beliefs.
What I wanted to say that all models are shit when it comes to fact checking or seeking truth. They are good for generating words that look like truth and in most cases are representing the overall consensus in that cultural area.
I asked about Tiananmen events the smallest deepseek model and at first it refused to talk about it (while thinking loud that it should not give me any details because it’s political) and then later when I tried to make it to compare these events to Solidarity events where former Polish government would use violence against the people, it would start talking about how sometimes the government has to use violence when the leadership thinks it’s required to bring peace or order.
Fair enough Mister Model made by autocratic country!
However. Compared to GPT and some others I tried it did count Rs in a word tomato. Which is zero. All others would tell me it has two R.
Deepseek R1 actually tells you why it’s giving you the output it’s giving you. It brackets it’s “thoughts” and outputs those before it gives you the actual output. It straight up tells you that it believes it is immoral or illegal to discuss the topic that is being censored.
I think the big question is how the model was trained. There’s thought (though unproven afaik), that they may have gotten ahold of some of the backend training data from OpenAI and/or others. If so, they kinda cheated their way to their efficiency claims that are wrecking the market. But evidence is needed.
Imagine you’re writing a dictionary of all words in the English language. If you’re starting from scratch, the first and most-difficult step is finding all the words you need to define. You basically have to read everything ever written to look for more words, and 99.999% of what you’ll actually be doing is finding the same words over and over and over, but you still have to look at everything. It’s extremely inefficient.
What some people suspect is happening here is the AI equivalent of taking that dictionary that was just written, grabbing all the words, and changing the details of the language in the definitions. There may not be anything inherently wrong with that, but its “efficiency” comes from copying someone else’s work.
Once again, that may be fine for use as a product, but saying it’s a more efficient AI model is not entirely accurate. It’s like paraphrasing a few articles based on research from the LHC and claiming that makes you a more efficient science contributor than CERN since you didn’t have to build a supercollider to do your work.
China copying western tech is nothing new. That’s literally how the elbowed their way up to the top as a world power. They copied everyones homework where they could and said, whatcha going to do about it?
Which is fine in many ways, and if they can improve on technical in the process I don’t really care that much.
But what matters in this case is that actual advancement in AI may require a whole lot of compute, or may not. If DeepSeek is legit, it’s a huge deal. But if they copied OpenAI’s homework, we should at least know about it so we don’t abandon investment in the future of AI.
All of that is a separate conversation on whether or not AI itself is something we should care about or prioritize.
So here’s my take on the whole stolen training data thing. If that is true, then open AI should have literally zero issues building a new model off of the full output of the old model. Just like deepseek did. But even better because they run it in house. If this is such a crisis, then they should do it themselves just like China did. In theory, and I don’t personally think this makes a ton of sense, if training an LLM on the output of another LLM results in a more power efficient and lower hardware requirement, and overall better LLM, then why aren’t they doing that with their own LLMs to begin with?.
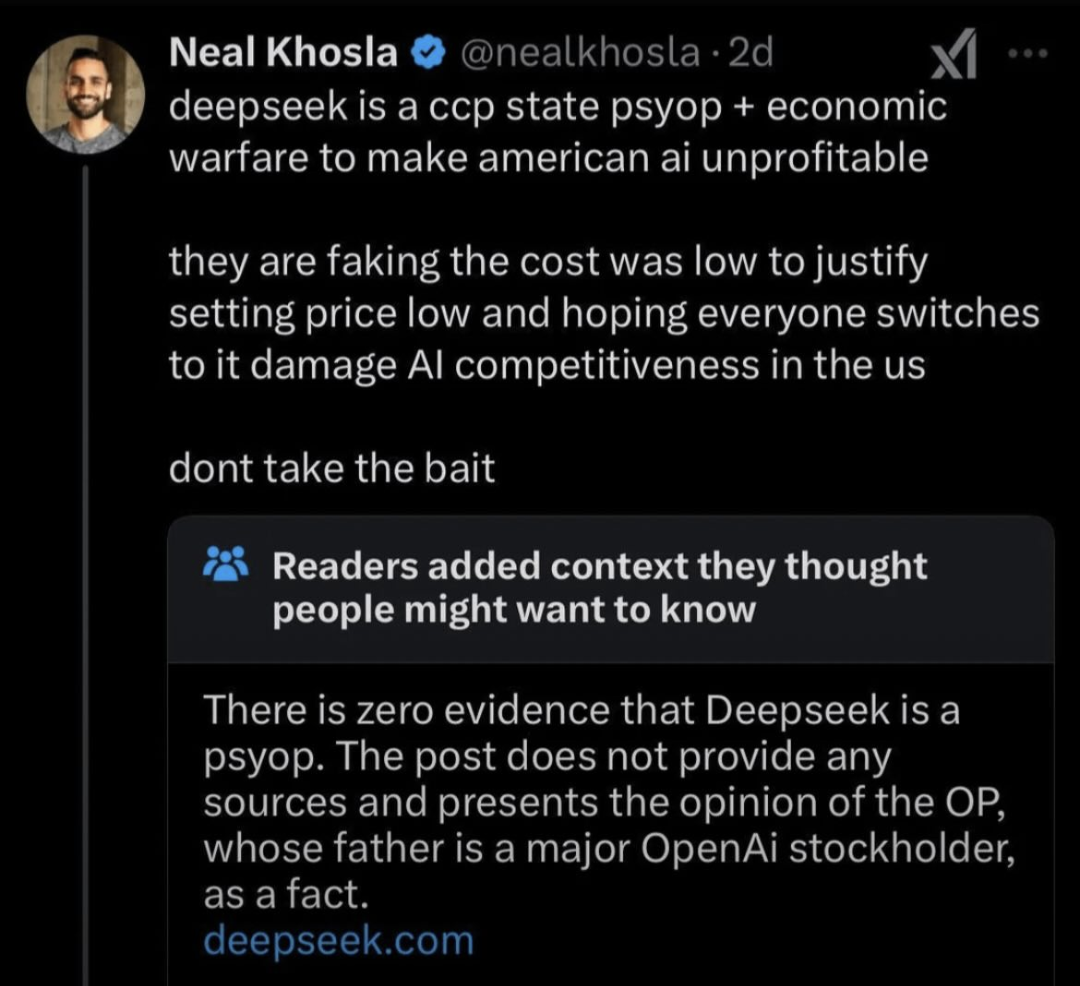
Assuming that poster is from the US, it is amazing that he calls another country a “cop state”.
Interesting that all the propaganda and subversiveness is coming from the US, not China. Having the opposite of the desired effect.
It looks like the rebut to the original post was generated by Deepseek. Does anyone wonder if Deepseek has been instructed to knock down criticism? Is its rebuttal even true?
His father’s firm was the first company to give seed funding to OpenAi
https://fortune.com/2023/12/04/khosla-ventures-openai-sam-altman/
https://www.businessinsider.com/openai-investor-vinod-khosla-ai-deflate-economy-25-years-2023-12
“lol”
So this guy is just going to pretend that all of these AI startups in thee US offering tokens at a fraction of what they should be in order to break-even (let alone make a profit) are not doing the exact same thing?
Every prompt everyone makes is subsidized by investors’ money. These companies do not make sense, they are speculative and everyone is hoping to get their own respective unicorn and cash out before the bill comes due.
My company grabbed 7200 tokens (min of footage) on Opus for like $400. Even if 90% of what it turns out for us is useless it’s still a steal. There is no way they are making money on this. It’s not sustainable. Either they need to lower the cost to generate their slop (which deep think could help guide!) or they need to charge 10x what they do. They’re doing the user acquisition strategy of social media and it’s absurd.
So this guy is just going to pretend that all of these AI startups in thee US offering tokens at a fraction of what they should be in order to break-even (let alone make a profit) are not doing the exact same thing?
fake it til you make it is a patriotic duty!
Are the robbers and thieves now infighting?
NOICE!
🍿
what’s that hissing sound, like a bunch of air is going out of something?
That’s the inward drawn air of bagholder buttholes puckering.
Also what’s more American than taking a loss to under cut competition and then hiking when everyone else goes out of business
It is capitalism when American parasite does this, mate.
Now apologize!
It’s capitalism when China does it, too. Regardless of China actually doing it with this ai thing or not.
China outwardly is a deeply capitalist country.
The major difference is China just replaced religion and freedumb™️ as the opiate of the masses with communism™️
I mean, you might as well call it the Walmart expansion model
to make american ai unprofitable
Lol! If somebody manage to divide the costs by 40 again, it may even become economically viable.
Environmentally viable? Nope!
nO. STahP! yOUre doING ThE CApiLIsM wrONg! NOw I dONt liKE tHe FrEe MaKrET :(
I do feel deeply suspicious about this supposedly miraculous AI, to be fair. It just seems too amazing to be true.
Open source means it can be publicly audited to help soothe suspicion, right? I imagine that would take time, though, if it’s incredibly complex
Open source is a very loose term when it comes to GenAI. Like Llama the weights are available with few restrictions but importantly how it was trained is still secret. Not being reproducible doesn’t seem very open to me.
True, but in this case I believe the also open sourced the training data and the training process.
Their paper outlines the training process but doesn’t supply the actual data or training code. There is a project on huggingface: https://huggingface.co/blog/open-r1 that is attempting a fully open recreation based on what is public.
You can run it yourself, so that rules out it’s just Indian people like the Amazon no checkout store was.
Other than that, yeah, be suspicious, but OpenAI models have way more weird around them than this company.
I suspect that OpenAI and the rest just weren’t doing research into less costs because it makes no financial sense for them. As in it’s not a better model, it’s just easier to run, thus it makes it easier to catch up.
Mostly, I’m suspicious about how honest the company is being about the cost to train the model, that’s one thing that is very difficult to verify.
They explained how you can train the model in order to create a similar A.I. on their white paper: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
Does it matter though? It’s not like you will train it yourself, and US companies are also still in the dumping stage.
It does, because the reason the US stock market has lost a billion dollars in value is because this company can supposedly train an AI for cents on the dollar compared to what a US company can do.
It seems to me that understating the cost and complexity of training would cause a lot of problems to the states.
It’s open source and people are literally self-hosting it for fun right now. Current consensus appears to be that its not as good as chatGPT for many things. I haven’t personally tried it yet. But either way there’s little to be “suspicious” about since it’s self-hostable and you don’t have to give it internet access at all so it can’t call home.
Is there any way to verify the computing cost to generate the model though? That’s the most shocking claim they’ve made, and I’m not sure how you could verify that.
If you take into account the optimizations described in the paper, then the cost they announce is in line with the rest of the world’s research into sparse models.
Of course, the training cost is not the whole picture, which the DS paper readily acknowledges. Before arriving at 1 successful model you have to train and throw away n unsuccessful attempts. Of course that’s also true of any other LLM provider, the training cost is used to compare technical trade-offs that alter training efficiency, not business models.






{kind=link}